AI技術の進歩により、手軽に「2次元画像から深度マップを生成する」ことが可能になりました。従来の画像解析だけでは困難だった処理を「AI技術で補完」することで、より精度の高い自律飛行制御の実現に期待が持てます。
本章では、すでに手元にある2次元動画を使って、深度マップに変換するまでの流れをご紹介いたします。
深度マップ
深度マップ(DepthMap)とは、3次元空間の奥行きを表現をするため、グレースケールの濃淡を使い対象物までの距離(深度)を表現したものです。
深度マップは、2枚のステレオ写真からも作成することができます。例としてWindows用のフリーウェアのステレオフォトメーカーを使って作成した深度マップがこちらです。カメラに近い部分ほど明るいピクセルになっていることが分かると思います。

深度マップ生成技術 MannequinChallenge
平面画像で奥行きを表現するために利用される深度マップですが、従来は両眼視差を利用したステレオカメラで撮影した画像やCGの3Dモデルなどから作られていました。最近ではAI技術が進歩したため、2次元画像からも容易に深度マップを作成することができるようになっています。今回はGoogleが開発した深度マップ生成技術である「マネキンチャレンジ -MannequinChallenge」が公開されていましたので、こちらを利用させていただくことにしました。
深度マップムービーの作成
GPU(nvidia cuda対応のビデオ カード)を搭載したPCで、Pythonがインストールされていれば、ローカル環境でもそのままコードを実行することができます。今回は、お手持ちのPCがこのような環境要件を満たさない方のために、Google Colabを使い、仮想サーバー上でコードを実行する方法を紹介いたします。
Windows10(64bit)のローカル環境で使用できるようにする方法については、前述のむっちゃんのステレオワールドさんのページ、Google公開のソフトを使った、2D画像からデプスマップの作成が参考になります。
準備1:コード(MannequinChallenge)のダウンロード
まず、Googleが公開している深度マップ作成用のコード(MannequinChallenge)を入手します。「Codeボタン」をクリックし、ZIPファイルでまるごとダウンロードし、適当な場所で解凍してください。
準備2:動画から連番ファイルを書き出す
まず、ベースとなる動画は手元にあったこちらのショートビデオ(トイドローンTelloのサークル機能を使用し、自動撮影した約38秒の動画)を利用しました。
Telloのサークル機能についてお知りになりたい場合は、ユーザーマニュアルをご覧ください。
次に動画ファイルから静止画の切り出しを行います。切り出しにはフリーウェアのFFmpegを利用しました。FFmpegはクロスプラットフォームソフトウェアです。FFmpegをインストール後、Windowsのコマンドプロンプトで以下のコマンドを実行します。
ffmpeg -i C:\sample\test.mp4 -r 3 C:\sample\save\%03d.jpg- 動画の保存先がC:\sample、ファイル名がtest.mp4、書き出し先がC:\sample\saveの場合
- 書き出し時のファイル名が3桁の連番数字+拡張子(.jpg)となるよう指定
- 1秒間あたり3コマずつ書き出しを行うように -r オプションに3を指定
約38秒の動画から秒3コマ間隔で書き出しを行った場合、このような116枚の静止画が作成されます。

準備3:Google Driveへファイルをアップロード
まず、Google Colabを使うためには、事前にGoogleアカウントを取得しておく必要があります。そして、そのアカウントでGoogle Driveにログインし、必要なファイルを全てアップロードしておきます。
以下、具体的な手順です。フォルダ名やファイル名は適時変更していただいて構いませんが、コード実行の中で使用されているファイルパスもそれに合わせて読み替えてください。
- マイドライブに解凍された「mannequinchallenge-master」フォルダをまるごとアップロードします。
- ドライブに作成された「mannequinchallenge-master」内の「test_data」フォルダに先ほど作成した静止画の連番ファイルを書き出したフォルダ(例:C:\sample\save)ごとアップロードします。
- 「test_data」フォルダ内にあるtest_davis_video_list.txtの内容を全て、「save」フォルダ内の静止画の連番ファイルの情報に差し替えます。
test_davis_video_list.txtに書き込む内容はこちらを参考にしてください。
test_data/save/001.jpg
test_data/save/002.jpg
test_data/save/003.jpg
(中略)
test_data/save/114.jpg
test_data/save/115.jpg
test_data/save/116.jpg準備4:Colabノートブックの作成
次にGoogle Colabを使用するための設定を行います。以降、Google Driveにログインしている前提での手順です。
- 最初にGoogle Colabにアクセスします。
- 「ファイル」メニューにある「ノートブックを新規作成」を選択します。
- 新しくブラウザにタブが追加され、Untitled0.ipynbという名前のColabのノートブックが作成されます。必要に応じでノートブック名を覚えやすいものに変更してください。
※この段階で、マイドライブに「Colab Notebooks」フォルダが作成され、その中にUntitled0.ipynb(新規ノートブック名)というファイルが自動で作成されます。再度このノートブックにアクセスする際は、このファイルをダブルクリックして使用してください。
- 「編集」メニューにある「ノートブックの設定」を選択します。
- 設定ダイアログが表示されたら「ハードウェアアクセラレータ」で「GPU」を選択し、「保存」をクリックします。
- 画面左側に縦に並んでいるアイコンの一番下にある「フォルダアイコン」をクリックします。自動的に「ランタイムに接続」が実行されます。
- ファイルの階層が表示されたら、「ドライブをマウント」アイコンをクリックします。
- 確認ダイアログが表示されたら、「GOOGLEドライブに接続する」をクリックします。
※ブラウザにGoogle Chromeを使用している場合のみ、コマンドボックスに<Googleドライブをマウントするためのコマンド>が自動入力された状態で停止しますので、次の操作を行ってください。
- まず、右側の実行ボタンをクリックします。
- 途中で、「Enter your authorization code」の入力が求められるので、入力欄の上に表示されているURLをクリックします。
- 別のタブでColabのノートブックで使用するアカウントの選択とログインが促されるため、指示に従って操作してください。「authorization code」が表示されたらそのコードをコピーして「authorization code」の入力ボックスにペーストします。
- Enterキーを押すと「Google Drive」のマウントが始まります。
- 「Google Drive」がマウントされたら、「drive」>「MyDrive」>「mannequinchallenge-master」の順にクリックし、アップロードしたファイルが確認できれば準備完了です。
- 一定の時間アクセスしないとランタイムが切断されますので、その場合は「フォルダアイコン」をもう一度クリックするか、「再接続」をクリックします。
準備5:機械学習モデルのダウンロード
機械学習モデルは、「mannequinchallenge-master」フォルダにあるシェルスクリプトファイルfetch_checkpoints.shを実行することで自動的にダウンロードできますが、Colabノートブックから実行しようとすると、スクリプトに記述されている新規フォルダ作成のステップで権限エラーが発生するため、以下の手順で登録することにしました。
- まず、マイドライブの「mannequinchallenge-master」フォルダ内に「checkpoints」フォルダを作成し、さらにその中に「test_local」フォルダを作成します。
- 次に、今回使用する学習モデル、best_depth_Ours_Bilinear_inc_3_net_G.pthを「Google APIs」から直接ダウンロードします。
- ダウンロードしてきた学習モデル(best_depth_Ours_Bilinear_inc_3_net_G.pth)を、先程作成した「test_data」フォルダ内にアップロードします。
コード(MannequinChallenge)の実行
それでは早速コードを実行していきます。
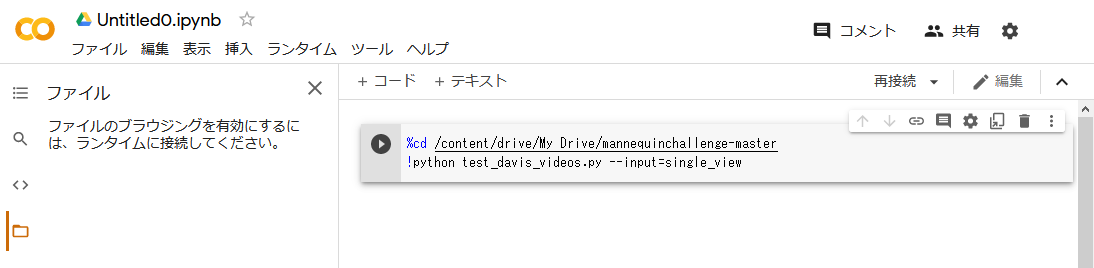
- 画面右側のコマンド入力欄に、以下のコマンドを入力します。
%cd /content/drive/My Drive/mannequinchallenge-master // 作業ディレクトリを移動
!python test_davis_videos.py --input=single_view // 深度マップ作成プログラムを実行- コマンドを入力したら、右側の実行ボタンをクリックします。
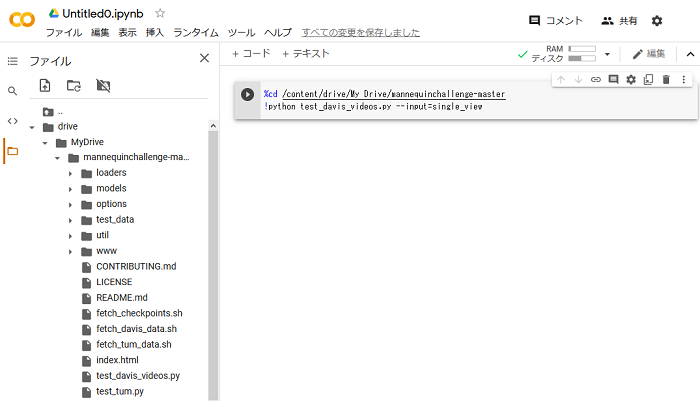
- 画面に「test_data/viz_predictions/save/116.jpg」の文字が表示されたら完了です。
あらかじめ「test_data」フォルダ内にあるtest_davis_video_list.txtに処理対象の画像ファイルをリストとして登録しているため、ワンクリックですべての作業が進行します。
このように、オリジナル画像の右側に深度マップが合成された画像となって出力されます。

※生成された深度マップ画像は、「mannequinchallenge-master」>「test_data」>「viz_predictions」>「save」フォルダ(連番ファイルを登録したフォルダ名と同名)に保存されています。
オリジナル画像付きの深度マップムービーを作成する
それでは仕上げとして、作成された深度マップの連番ファイルを使って動画を作っていきます。まずは書き出された画像をそのまま使用し、オリジナル画像付きの深度マップムービーを作成してみます。静止画から動画を作成する場合も、書き出し時に利用したFFmpegが利用できます。Windowsの場合、コマンドプロンプトで以下のコマンドを実行します。今回、秒3コマで書き出しを行いましたので、動画に戻す場合も3コマで1秒となるように設定します。
ffmpeg -r 3 -i C:\sample\%03d.jpg C:\sample\save\test.mp4- 静止画の保存先がC:\sample、動画の書き出し先がC:\sample\save、ファイル名がtest.mp4の場合
- 取り込む静止画のファイル名が3桁の連番数字+拡張子(.jpg)となるよう指定
- 静止画3コマを使って動画1秒分の生成を行うように -r オプションに3を指定
書き出された動画は元の動画と同じ約38秒となりました。秒3コマの動画ですので、動きはギコチがないものとなっていますが、今回行う検証のための動画としては問題ありません。
トリミングした深度マップムービーを作成する
現在は2種類の画面が合成されたままの状態なので、このままでは既存の自律飛行プログラムに取り込むことができません。そこでffmegを使ってトリミング処理を施し、検証で使用したい右半分だけの動画を作成することにします。Windowsのコマンドプロンプトに以下のコマンドを入力し実行します。
ffmpeg -i C:\sample\test.mp4 -vf crop=512:288:512:0 C:\sample\save\test.mp4- 動画の保存先がC:\sample、書き出し先がC:\sample\save、ファイル名はいずれもtest.mp4の場合
- -vf crop=出力動画の幅 : 出力動画の高さ : 切り取る左側の幅 : 切り取る上部の高さ
処理はあっという間に終わりました。トリミングにより右半分だけになった動画がこちらです。
こうして深度マップに変換された動画を見てみると、改めて対象物のシルエットが「カラーリングや模様」に影響されることなく、クッキリと映し出されている様子がおわかりいただけると思います。
ここまでが、2次元動画を深度マップに変換するまでの流れとなります。操作に馴れてしまえば、一連の作業は5分程度で完了することができます。
深度マップムービーの画像処理への活用
続いて次章では、実際に弊社が小型ドローンの屋内自律飛行のために使用した(マーカーなど、対象物の位置捕捉用)プログラムを使い、これまでの「画像処理のみの場合」と「深度マップと組み合わせた場合」とで、どのような認識精度の違いが出るのかについて比較していきます。