自動車のナンバープレート解析の活用及び技術検証
本記事では画像処理を用いた自動車のナンバープレート(自動車登録番号表)の読み取りと解析について紹介します。
- 駐車場への車両の出入庫を管理する
- 許可のない車両の不法侵入を検知・通知する
- 駐車車両を記録し訪問者の属性を割り出す等
上記のように我々の生活の中で幅広い使用用途が考えられます。
またその場合、野外での利用が想定されます。そのため今回は以下2点をを条件としました。
- 安価&コンパクトな機材を用いてどこにでも簡単に設置できること
- インターネットに接続できる環境があればどこからでもナンバープレートの読み取り結果を確認できること
PythonとOpenCVを利用したナンバープレートの読み取り
今回の画像処理では、PythonとOpenCVを利用しました。
下記「OpenCV 3 License Plate Recognition Python」よる海外のナンバープレートの解析事例に注目し、こちらの事例をベースとして日本のナンバープレートを正しく読み取れるようにカスタマイズしていきました。
今回の開発による解析の結果、下記画像のようにおおよそ正しく読み取ることができました。日本独自の文字であるひらがなの読み取り精度は調整する必要があることも分かります。


ナンバープレートの解析と出力
具体的な開発手順については以下に紹介していきます。
開発環境
- OS: Windows10
- 統合開発環境: anaconda 4.6.14
- 画像処理ライブラリ: OpenCV 3.4.2
使用ライブラリ
今回はGoogle スプレッドシート出力用ライブラリを使用しています。また、今回読み取った情報はGoogleスプレッドシートへ出力します。※解析結果のテキスト部分のみ(数字など)
- oauth2client
- httplib2
- gspread
ナンバーを読み取るための画像加工
ナンバープレートを読み込む
まずk-NNの学習データを読み込みます。(※k-NNの学習データについては後述)
ナンバーを読み取るための画像加工を行う
次に自動車のナンバープレートが写った静止画を読み込み、読み取るための画像加工を行います。

上記のグレースケールに変換した画像を更にコントラストをあげます。具体的にはグレー画像とオープニングした画像の差をグレー画像に追加し、グレー画像とクロージングした画像の差を除いています。そしてコントラストをあげた画像をぼかし(GaussianBlur)、二値化(adaptiveThreshold) します。

加工された画像からナンバーの位置を絞り込み、判定する
こうして二値化された画像から輪郭を検出し、その輪郭の外接矩形を文字として想定します。

そこから更に外接矩形の面積、高さ、幅、縦横比を一定の範囲内のものに絞ります。
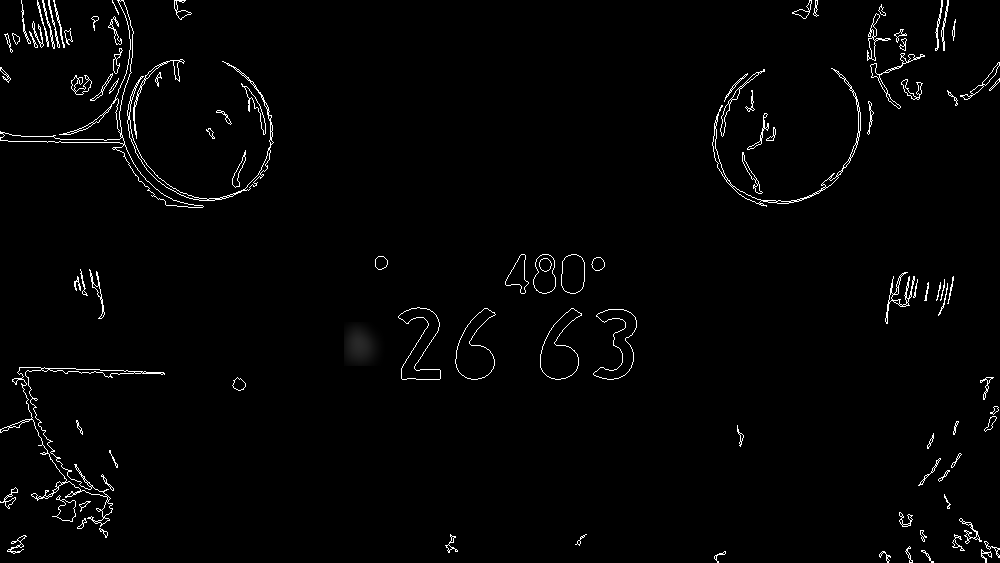
一つ目の文字と続く文字間の角度と間隔、大きさの変化の度合いが一定の範囲のものをさらに絞り込みます。
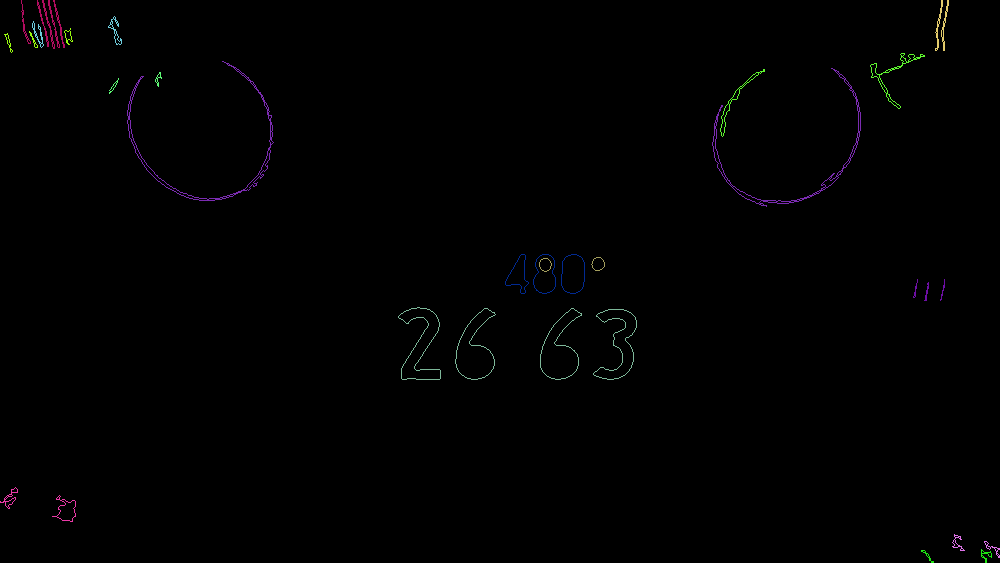
絞り込まれたものをナンバープレートとして判定し、読み取り処理を行います。
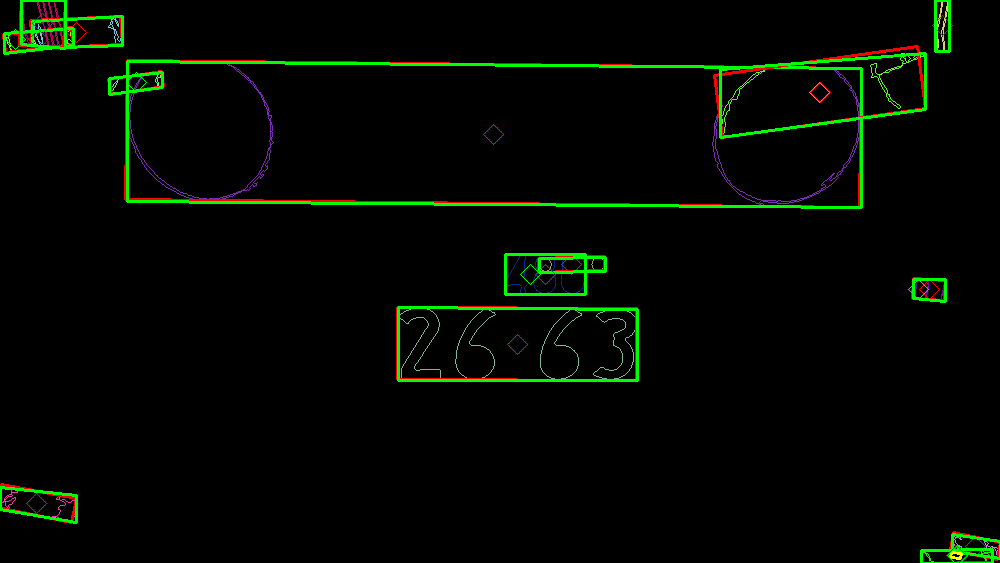
日本のナンバープレートの読み取りと解析
日本のナンバープレートへの対応
日本のナンバーはメインとなる4桁の数字【一連指定番号】以外に、種別を表す【分類番号】、【ひらがな】、【地名】があります。 一連指定番号と分類番号のそれぞれを認識できたら、お互いの距離や角度を判断し、ひとまとめにして解析を進めます。
一連指定番号はどのような桁数でも2番目と3番目の間隔は他よりも大きいので、そこが一連指定番号の中心と判断します。一桁のナンバーは、・(ナカグロ)が3つあり・の2番目と3番目の間が開いています。4桁の場合に付けられる中心の、「-」は無視します。
一連指定番号、分類番号、ひらがな、地名の4つの要素の位置は統一されています。そのため、一連指定番号と分類番号の位置と大きさから、ひらがなや地名のある場所とナンバー全体の範囲を判断することができました。
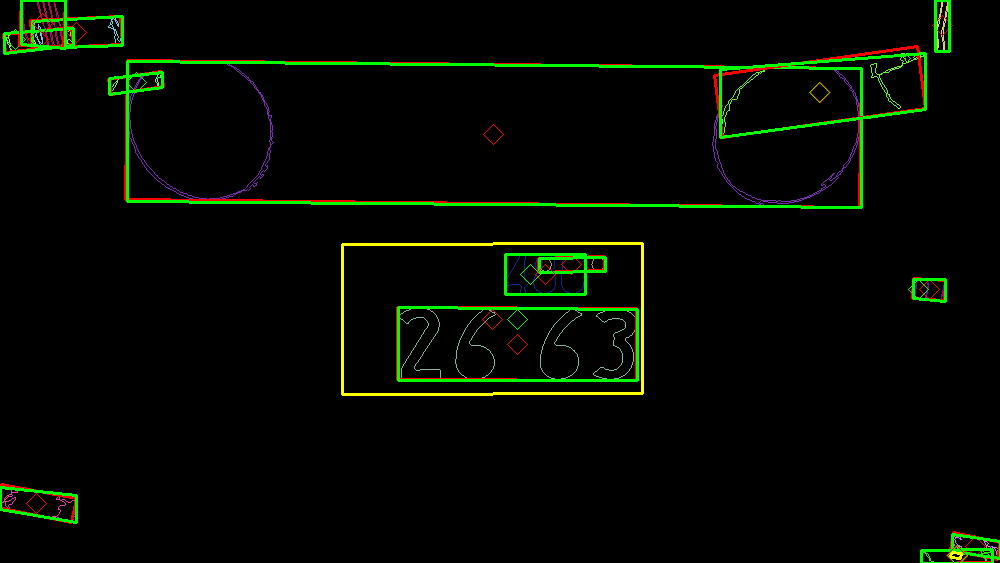

日本独自の文字を読み取る
ナンバープレートとして想定した部分を改めて画像処理をし、k近傍法(k-nearest neighbor algorithm)で文字を読み取ります。
その前に、海外と日本では数字であっても文字の形に違いがあるため、精度を高めるため日本のナンバーに利用されている文字で学習データを作る必要があります。
下記画像から分かるように、海外のナンバー(左側)と日本のナンバー(右側)では文字の形に違いがあります。例えば「6」は丸みに大きな違いがあるため、海外のナンバーを学習させていたのでは誤判定の原因になってしまいます。

日本で使われている文字で学習データを作成、学習させる
ディレクトリ名から正解データを作るので、まずは0~9までのディレクトリを用意します。

そして各フォルダに対応する数字の画像を切り抜き、保存します。

切り抜く文字の範囲はプログラムと同じように検知させ、縮小拡大するサイズはもとのプログラムのサイズのままにしました。
同じようにして地名部分やひらがな部分も作成、学習させることができます。

Python 3では何も気にすることなく日本語を扱え困ることがありませんでしたが、cv2では日本語のディレクトリ名・ファイル名に対応していないようで、下記を参考にファイルの読み込みと書き込みを別途定義しました。
そして処理フローの一番最初で読み込む学習データをこちらのできあがったデータに変更します。ひらがな部分と地名部分も同時に読み込みます。
数字部分はプログラムと同様の範囲で文字の位置を判断し読み取りますが、ひらがな部分と地名部分については一続きで書けるアルファベットと異なり、細かい輪郭のまとまりが一文字となります。メインの番号や分類番号の位置やナンバー全体の範囲からおおよその位置がわかるので、その中にある輪郭をまとめて文字としました。
ナンバープレート読み取り結果の出力
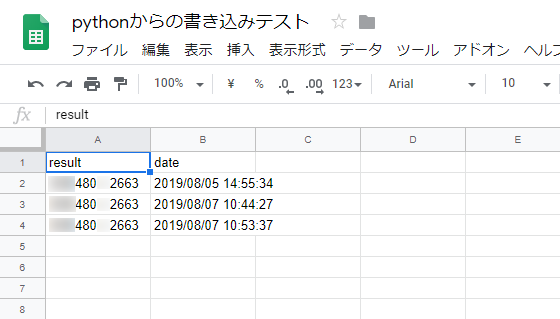
最後に、解析結果をどこでも確認できるようGoogleスプレッドシートに書き込めるようにします。Googleスプレッドシートに書き込む方法は(出典)Google スプレッドシートをpythonで操作する|Qiitaを参考にしました。
結果は以下のように書き込まれていきます。
ちなみに、最初はナンバーの位置を特定した後、読み取り結果を画像に直接書き出していました。

その際、OpenCVで結果画像に日本語を記入しようとすると???と文字化けしてしまったため、下記記事を参考に日本語に対応させました。
自動車のナンバープレート解析の実用化に向けて
夜間のナンバー読み取りへの対応が課題
ナンバープレートを斜めに捉えてしまった場合や、夜など暗い場面でのナンバー読み取りに対応することが今後の課題です。今回は使用しませんでしたが、夜間でも精度が高くナンバーが解析できる以下のようなライブラリもあるようです。
cloudのサブスクリプションで、月1000回の解析までは無料です。また一時間に一回ペースの認識であれば継続して無料で使用できます。
 (出典)Cloud API|OPENALPR
(出典)Cloud API|OPENALPR
暗い場面だけでなく日本のナンバープレートに対応しており、車種など車の詳細まで解析することができます。
ただし、毎回ナンバーの判定のために一から上記ライブラリに処理を任せるとそれだけで処理時間や価格面でのコストが高くなってしまいます。そのためコストパフォーマンスも意識したシステムとする場合は、例えば
- 前処理として、今回のような映像・画像内にナンバー自体があるか否かなどの前処理をした後
- ナンバーがある場合に上記のようなサービス(API)に処理を投げる
などの組み合わせが有効と考えられます。使用するシーンや内容に合わせた組み合わせで対応すれば、よりコストを抑え、より精度の高い解析を行うことができます。
ご当地ナンバーの対応
2018年10月からご当地ナンバーが開始され今後も増えていくことが予想されます。ご当地ナンバーとは国土交通省が自動車のナンバープレートに表示する地名について、独自の地名を定められるよう新たに開始した制度です。この制度により、対応しなければならない文字(地名)が増え学習コストも高くなってしまいます。
そのため、日本のナンバープレートの解析にはk-nnを利用するより、ocrで読み取ることができればそちらの方が適していると考えられます。
 (出典)地方版図柄入りナンバープレートデザイン|国土交通省
(出典)地方版図柄入りナンバープレートデザイン|国土交通省